Content tagged programming
Tags
Months
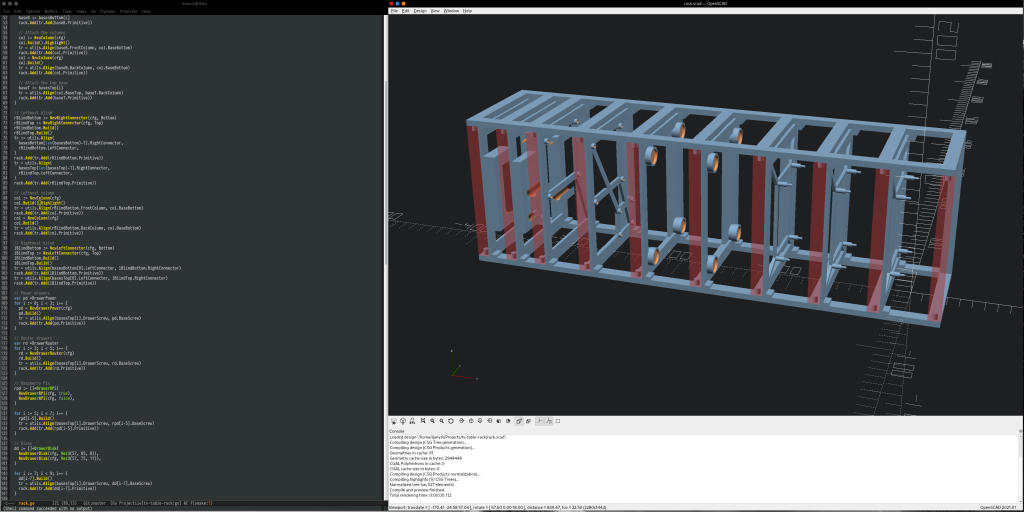
OpenSCAD is awesome. It gives you the ability to code up your 3D models and keep them readably under version control. But, despite the coolness, OpenSCAD has a bunch of limitations. This post introduces a system called GhostSCAD as a way around some of them.

This blog is built using a customized version of Coleslaw - a static Common Lisp blogware. This post shares some insight into how it is done.
Set up a virtual machine with 4KB of RAM by calling magic IOCTLs on /dev/kvm and make it run a program that writes to an IO port that is then intercepted by the hypervisor.