Intro
I have recently stumbled upon two articles (1, 2) treating about running TensorFlow on CPU setups. Out of curiosity, I decided to check how the kinds of models I use behave in such situations. As you will see below, the results were somewhat unexpected. I did not put in the time to investigate what went wrong, and my attempts to reason about the performance problems are pure speculations. Instead, I just run my models with a bunch of different threading and OpenMP settings that people typically recommend on the Internet and hoped to have a drop-in alternative to my GPU setup. In particular, I did not convert my models to use the NCHW format as recommended by the Intel article. This data format conversion seems to be particularly important, and people report performance doubling in some cases. However, since my largest test case uses transfer learning, applying the conversion is a pain. If you happen to know how to optimize the settings better without major tweaking of the models, please do drop me a line.
Testing boxes
- ti: My workstation
- GPU: GeForce GTX 1080 Ti (11GB, Pascal)
- CPU: 8 OS CPUs (Core i7-7700K, 1 packages x 4 cores/pkg x 2 threads/core (4 total cores))
- RAM: 32GB (test data loaded from an SSD)
- p2: An Amazon p2.xlarge instance
- GPU: Tesla K80 (12GB, Kepler)
- CPU: 4 OS CPUs (Xeon E5-2686 v4)
- RAM: 60GB (test data loaded from a ramdisk)
- m4: An Amazon m4.16xlarge instance
- CPU: 64 OS CPUs (Xeon E5-2686 v4, 2 packages x 16 cores/pkg x 2 threads/core (32 total cores))
- RAM: 256GB (test data loaded from a ramdisk)
TensorFlow settings
The GPU flavor was compiled with CUDA support; the CPU version was configured with only the default settings; the MKL flavor uses the MKL-ML library that the TensorFlow's configuration script downloads automatically;
The GPU and the CPU setups run with the default session settings. The other configurations change the threading and OpenMP setting on the case-by-case basis. I use the following annotations when talking about the tests:
[xC,yT]means theKMP_HW_SUBSETenvvar setting and the interop and intraop thread numbers set to 1.[affinity]means theKMP_AFFINITYenvvar set togranularity=fine,verbose,compact,1,0and the interop thread number set to 2.[intraop=x, interop=y]means the TensorFlow threading setting and no OpenMP setting.
More information on controlling thread affinity is here, and this is an article on managing thread allocation.
Tests and Results
The test results are the times it took to train one epoch normalized to the result obtained using the ti-gpu configuration - if some score is around 20, it means that this setting is 20 times slower than the baseline.
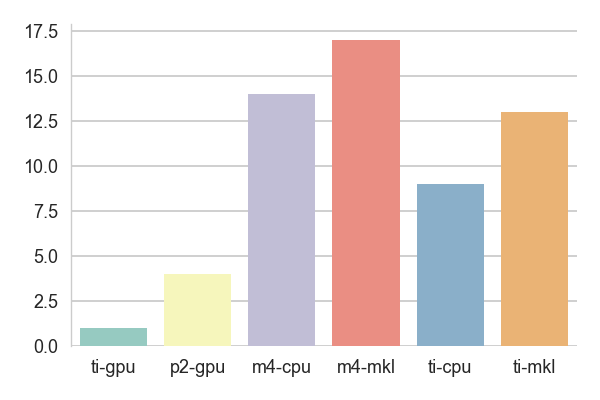
The first test uses the LeNet architecture on the CIFAR-10 data. The MKL
setup run with [4C,2T] on ti and [affinity] on m4. The results are
pretty surprising because the model consists of almost exclusively the
operations that Intel claims to have optimized. The fact that ti run faster
than m4 might suggest that there is some synchronization issue in the graph
handling algorithms preventing it from processing a bunch of tiny images
efficiently.
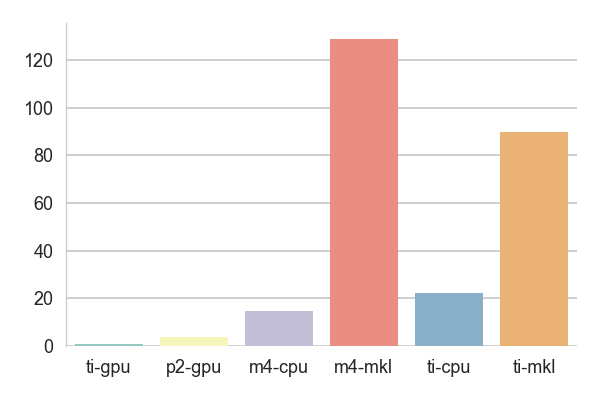
The second test is my road sign classifier. It uses mainly 2D convolutions and pooling, but they are interleaved with hyperbolic tangents as activations as well as dropout layers. This fact probably prevents the graph optimizer from grouping the MKL nodes together resulting with frequent data format conversions between NHWC and the Intel's SIMD friendly format. Also, ti scored better than m4 for the MKL version but not for the plain CPU implementation. It would suggest inefficiencies in the OpenMP implementation of threading.
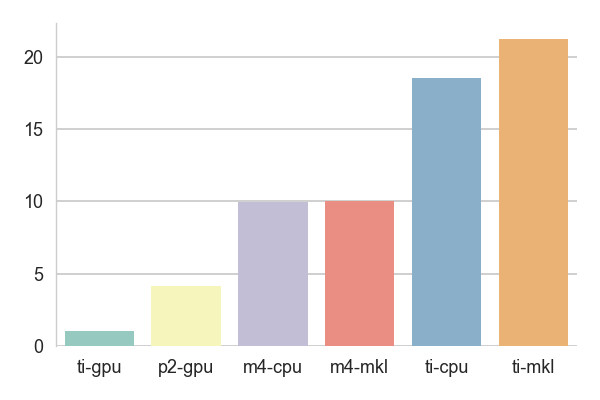
The third and the fourth test run a fully convolutional neural network
besed on VGG16 for an image segmentation project. Apart from the usual suspects,
this model uses transposed convolutions to handle learnable upsampling. The
tests differ in the size of the input images and in the sizes of the weight
matrices handled by the transposed convolutions. For the KITTI dataset, the
ti-mkl config run with [intraop=6, interop=6] and m4-mkl with
[affinity].
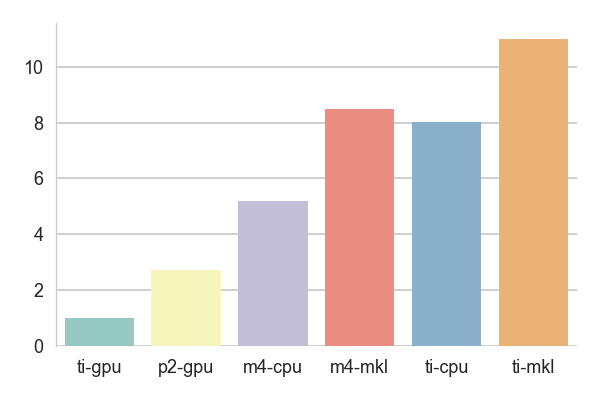
For the Cityscapes dataset, ti-mkl run with [intraop=6, interop=6] and
m4-mkl run with [intraop=44, interop=6]. Here the MKL config was as fast
as the baseline CPU configs for the dataset with fewer classes and thus smaller
upsampling layers. The slowdown for the dataset with more classes could probably
be explained by the difference in the handling of the transposed convolution
nodes.
Conclusions
It was an interesting experience that arose mixed feelings. On the one hand, the best baseline CPU implementation was at worst two to four times slower with only the compiler optimization than Amazon P2. It's a much better outcome than I had expected. On the other hand, the MKL support was a disappointment. To be fair, in large part it's probably because of my refusal to spend enough time tweaking the parameters, but hey, it was supposed to be a drop-in replacement, and I don't need to do any of these when using a GPU. Another reason is that TensorFlow probably has too few MKL-based kernels to be worth using in this mode and the frequent data format conversions kill the performance. I have also noticed the MKL setup not making any progress with some threading configurations despite all the cores being busy. I might have hit the Intel Hyperthreading bug.
Notes on building TensorFlow
The GPU versions were compiled with GCC 5.4.0, CUDA 8.0 and cuDNN 6. The ti configuration used CUDA capability 6.1, whereas the p2 configuration used 3.7. The compiler flags were:
- ti:
-march=core-avx-i -mavx2 -mfma -O3 - p2:
-march=broadwell -O3
The CPU versions were compiled with GCC 7.1.0 with the following flags:
- ti:
-march=skylake -O3 - m4:
-march=broadwell -O3
I tried compiling the MKL version with the additional -DEIGEN_USE_MKL_VML flag
but got worse results.
The MKL library is poorly integrated with the TensorFlow's build system. For
some strange reason, the configuration script creates a link to libdl.so.2
inside the build tree which results with the library being copied to the final
wheel package. Doing so is a horrible idea because in glibc libdl.so mostly
provides an interface for libc.so's private API so a system update may break
the TensorFlow installation. Furthermore, the way in which it figures out which
library to link against is broken. The configuration script uses the locate
utility to find all files named libdl.so.2 and picks the first one from the
list. Now, locate is not installed on Ubuntu or Debian by default, so if you
did not do:
]==> sudo apt-get install locate
]==> sudo updatedb
at some point in the past, the script will be killed without an error message leaving the source tree unconfigured. Moreover, the first pick is usually a wrong one. If you run a 64-bit version of Ubuntu with multilib support, the script will end up choosing a 32-bit version of the library. I happen to hack glibc from time to time, so in my case, it ended up picking one that was cross-compiled for a 64-bit ARM system.
I have also tried compiling Eigen with full MKL support as suggested in this thread. However, the Eigen's and MKL's BLAS interfaces seem to be out of sync. I attempted to fix the situation but gave up when I noticed Eigen passing floats to MKL functions expecting complex numbers using incompatible data types. I will continue using the GPU setup, so fixing all that and doing proper testing was way more effort than I was willing to make.
Node 14.07.2017: My OCD took the upper hand again and I figured it out. Unfortunately, it did not improve the numbers at all.